

Understanding the Fundamentals of Vector Search and its Role in Semantic Matching
At its core, vector search revolutionizes the way information retrieval works by leveraging the power of numerical representations called embeddings. These embeddings capture the essence of data points-whether words, images, or documents-in a multi-dimensional vector space. By mapping complex inputs to vectors, the search process turns into a mathematical comparison of proximity rather than relying on exact keyword matches. This allows systems to understand the underlying semantics and context, enabling more intuitive and accurate results that align with user intent, even if explicit keywords are missing.
Key components of this approach include:
- Embedding generation: Converting raw data into vectors that represent semantic meaning.
- Vector indexing: Organizing vectors efficiently to enable fast searches in large datasets.
- Similarity metrics: Calculating distances such as cosine similarity or Euclidean distance to assess how closely related vectors are.
To illustrate, consider the following comparison of conventional keyword search versus vector search:
| Aspect | Keyword Search | Vector Search |
|---|---|---|
| Matching Basis | Exact keyword presence | Semantic similarity |
| Result Quality | Surface-level, often limited | Context-aware, nuanced |
| Handling Synonyms | Poor | Excellent |
| Scalability | Depends on indexing | Optimized for large datasets |
Ultimately, vector search forms the backbone of modern semantic matching solutions. It empowers applications like proposal engines, natural language processing, and image retrieval to deliver results that genuinely understand and anticipate user needs.
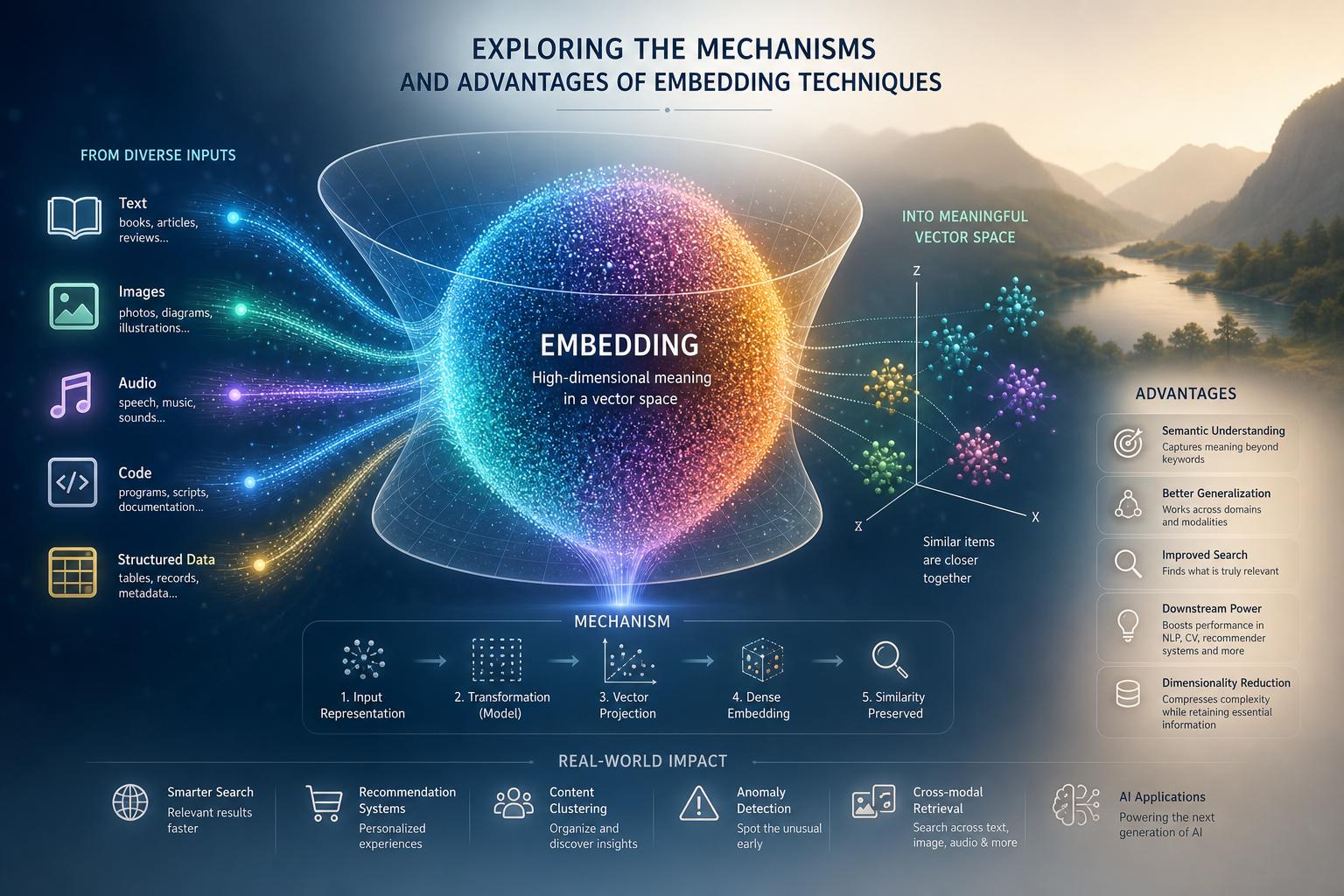
Exploring the Mechanisms and Advantages of Embedding Techniques
Embedding techniques transform complex information-such as text, images, or audio-into multi-dimensional vector representations, allowing machines to understand semantic meaning beyond simple keyword matching. By mapping data to a continuous vector space, embeddings capture subtle relationships like synonyms, contextual relevance, and even analogies, which traditional search methods often overlook. This nuanced understanding fuels the power of vector search systems that excel in retrieving results based on meaning rather than just exact terms, enhancing the accuracy of semantic matching.
Advantages of embedding techniques include:
- Context-aware retrieval: Embeddings consider the larger context, enabling systems to find relevant information even with ambiguous or sparse queries.
- Scalability and efficiency: Vectors allow efficient indexing and similarity computation using algorithms such as cosine similarity or nearest neighbor search.
- Cross-modal applications: Embeddings support integration across data types, linking text to images or audio, enriching search capabilities.
| Embedding Technique | Primary Application | Key Benefit |
|---|---|---|
| Word2Vec | Text semantics | Captures word analogies |
| image Embeddings | Visual search | Enables similarity matching |
| Audio Embeddings | Speech recognition | Robust to noise |
Leveraging Vector Search for Enhanced Information retrieval and Contextual Relevance
Vector search transforms traditional keyword-based retrieval by leveraging the power of numerical embeddings that capture the semantic essence of data points. Unlike conventional exact-match algorithms, vector-based retrieval interprets the underlying meaning, enabling systems to locate information that is contextually relevant even when the explicit keywords differ. This allows users to achieve nuanced search results that go beyond surface-level matches, improving precision in domains such as natural language processing, multimedia retrieval, and recommendation engines.
The benefits of vector search become especially evident when dealing with complex queries or large, heterogeneous datasets. Key advantages include:
- Contextual Relevance: Retrieves results based on overall meaning rather than keyword overlap.
- Robustness to Variability: Handles synonyms, typos, and paraphrases effectively.
- Scalability: Efficient algorithms support rapid searching across massive vector spaces.
- Flexibility: Applicable to text,images,audio,and mixed modalities.
| Feature | Vector Search | Traditional Keyword |
|---|---|---|
| match Type | Semantic | syntactic |
| Tolerance to Variations | High | Low |
| Use Cases | Multimedia,NLP,Recommendations | Web Search,Document Indexing |
| processing Complexity | Higher | Lower |
Best Practices for Implementing and Optimizing Vector search Systems in Real-World Applications
Adopting efficient data structures and indexing methods is pivotal in ensuring fast and scalable vector searches. Commonly leveraged structures include Approximate Nearest Neighbor (ANN) algorithms such as HNSW or Faiss,which balance search accuracy with computational efficiency. It’s essential to tailor these indexing algorithms to the datasetS size and dimensionality while continuously monitoring latency and throughput metrics in real-world scenarios. Implementing incremental updates rather than full re-indexing can drastically reduce downtime and improve the freshness of search results.
Optimization also hinges on careful management of embedding quality and dimensionality. Dimensionality reduction techniques like PCA or UMAP can enhance performance without sacrificing semantic richness. Beyond computational concerns, consider application-specific factors such as query diversity and relevance feedback loops. Incorporating robust evaluation frameworks - with offline benchmarks and real-time user interaction analytics – helps fine-tune system parameters,delivering results that are both contextually accurate and operationally sustainable.