

Understanding the Role of Retrieval in Enhancing AI Code Comprehension
Unlocking the full potential of AI in code comprehension requires more than just pattern recognition-it demands a deep retrieval mechanism that connects queries to relevant segments of code and documentation. By integrating retrieval systems directly into AI workflows, these models don’t merely guess or generate plausible explanations; they access precise, grounded information drawn from the actual codebase. This approach ensures answers are contextual, accurate, and directly traceable to the source, thereby elevating the reliability of AI-assisted growth processes. Retrieval enhances AI’s ability to navigate complex dependencies, clarify ambiguous logic, and interpret evolving codebases with an unprecedented level of precision.
Key advantages of retrieval-based approaches include:
- Contextual Accuracy: Retrieves exact code snippets or documentation relevant to the query, reducing hallucination in AI responses.
- Improved Debugging: Pinpoints where bugs or inconsistencies arise by linking questions to concrete code lines.
- Scalability: Enables AI systems to handle large and constantly changing codebases without losing fidelity.
- Faster Knowledge Transfer: Facilitates onboarding by allowing instant access to the most pertinent code explanations.
| Aspect | Conventional AI | Retrieval-Enhanced AI |
|---|---|---|
| Information Source | Learned patterns only | Direct codebase access |
| Response Reliability | probabilistic guesses | Grounded facts |
| Handling Ambiguity | Ofen confused | Contextually clear |
| Update Frequency | Periodic retraining | Real-time retrieval |
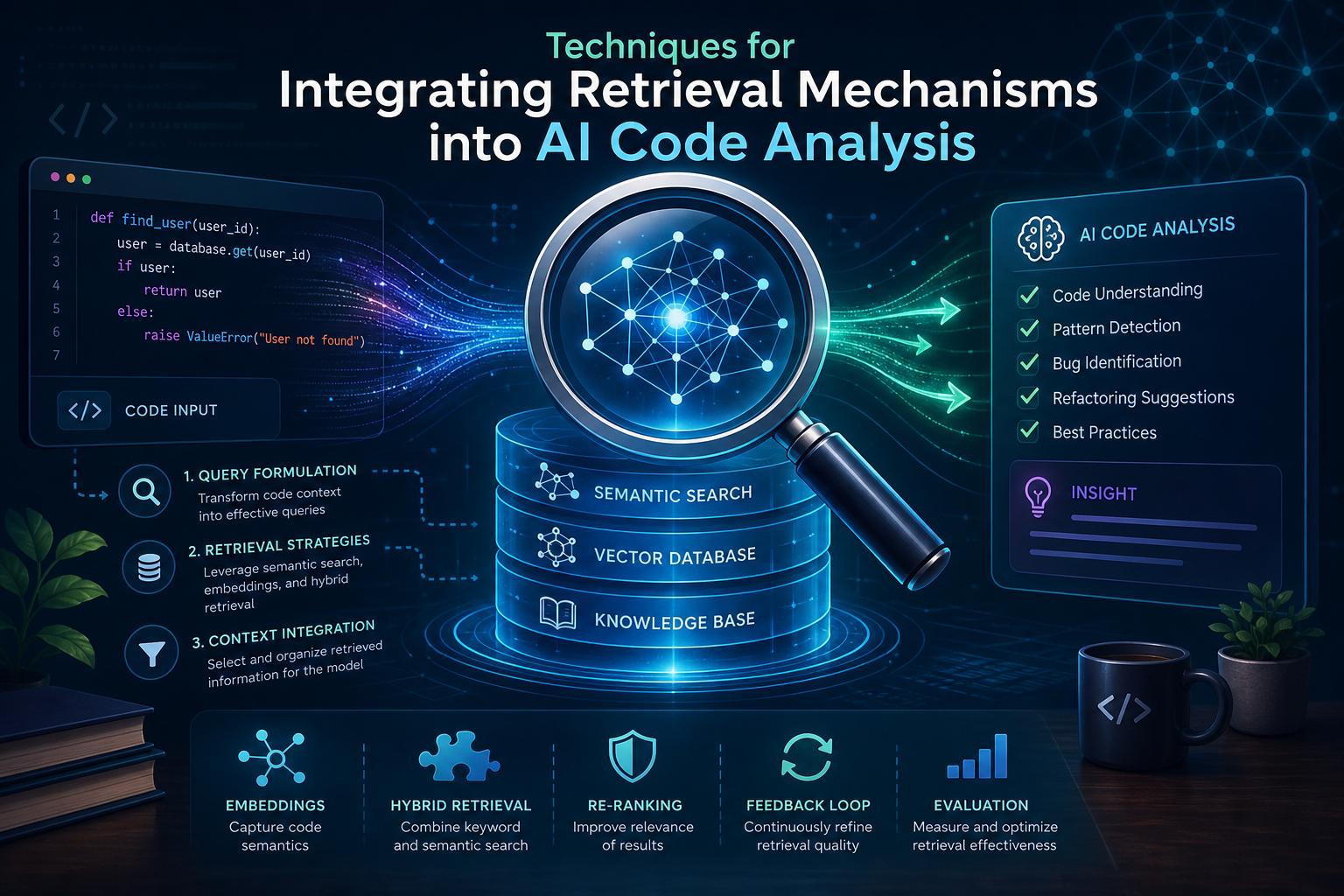
Techniques for Integrating Retrieval Mechanisms into AI Code Analysis
Embedding retrieval mechanisms into AI-driven code analysis transforms passive code understanding into an active knowledge exploration process. By leveraging indexed fragments of code, documentation, and past commit messages, AI models can ground their responses in concrete evidence drawn directly from your repository. This approach not only enhances accuracy but also enables context-aware suggestions that respect the nuances of your unique codebase. Key methods include embedding-based similarity search, where vectorized code snippets are matched against queries, and hybrid retrieval, combining symbolic and neural search to balance precision with recall.
Integrating these retrieval techniques can be structured through several practical strategies:
- Modular embedding stores: Partition your codebase by functionality, indexing each module separately for faster, more relevant retrieval.
- Dynamic update pipelines: Automatically refresh indexes with every commit to keep the retrieval layer current and reflective of the latest changes.
- Relevance feedback loops: Use AI’s interaction history to refine retrieval results based on user corrections and preferences.
| Technique | Advantage | Use Case |
|---|---|---|
| Embedding Vector Search | High semantic relevance | Identifying similar code patterns |
| Hybrid Symbolic-Neural Retrieval | Balanced precision and recall | Complex query resolution |
| Incremental Indexing | Up-to-date knowledge base | Continuous integration pipelines |
Evaluating the Accuracy and Reliability of AI-Driven Codebase Responses
Assessing the precision of AI-generated answers within complex codebases requires a structured approach that goes beyond surface-level validation. The intrinsic strength of AI in this domain lies in its capability to reference actual segments of the underlying code when formulating responses, thus anchoring its outputs in reality rather than speculation. Critical to this process is the implementation of context-aware retrieval systems that enable AI to sift through large-scale repositories with accuracy. These systems ensure that the answers are not only relevant but verifiable against the actual code, reducing the risk of misinformation. The evaluation metrics should thus focus on factual alignment-how well the AI’s responses reflect true code functionalities and recent updates.
Reliability hinges on an AI model’s consistency and error-resilience across diverse query types and programming languages within the codebase. Key factors influencing trustworthiness include:
- Update Frequency: Regular syncing with the latest code commits.
- Handling Ambiguity: Ability to clarify or flag unclear questions.
- Traceability: Providing source line references for every response.
| Evaluation Criteria | Impact on Accuracy | Example Challenge |
|---|---|---|
| Data Recency | High | Answers outdated after recent refactor |
| Context Depth | Moderate | Misinterpretation of nested functions |
| Error Flagging | high | Failing to identify ambiguous queries |
Best Practices for Leveraging Retrieval-Enabled AI to Optimize Software Development
Maximizing the synergy between retrieval-enabled AI and software development workflows hinges on strategic integration and disciplined data management. Developers should prioritize creating thorough, structured, and frequently updated document repositories that facilitate precise retrievals. Embedding context-aware search capabilities into code editors can dramatically reduce lookup times, thereby accelerating debugging and feature implementation. Moreover, integrating AI insights directly into version control and CI/CD pipelines ensures that suggestions and automated fixes are grounded in the most current codebase state, minimizing discrepancies and technical debt.
To fully harness the benefits of these systems, teams must adopt clear guidelines on data curation and prompt engineering tailored to their unique environments. Emphasizing transparency and auditability of AI-generated recommendations builds trust and accountability among developers. Consider the following key areas:
- Document Quality: Maintain clean, well-annotated code docs and changelogs to improve retrieval accuracy.
- Context Injection: Use dynamic context windows that reflect recent commits or active branches.
- Feedback Loops: Implement continuous feedback mechanisms to refine AI responses and align them with developer intent.
- Security Filters: Ensure sensitive data is excluded from retrieval queries to protect proprietary information.
| Best Practice | Impact | Implementation Tip |
|---|---|---|
| up-to-date Documentation | Enhances answer relevance | Automate doc generation with each commit |
| Context-aware Queries | Improves precision in suggestions | Embed real-time environment metadata |
| Feedback Integration | Continuously optimizes AI outputs | Use developer annotations and corrections |
| Data Privacy Controls | Safeguards codebase integrity | Whitelist and blacklist sensitive files |